
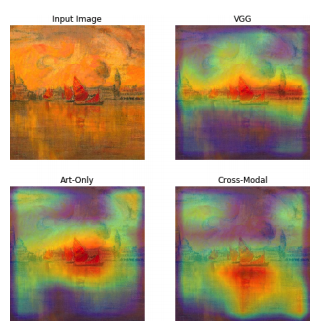
Analyzing 18th-20th Century Art and Music with Contrastive Cross-Modal Learning
Master's Thesis
Vivien Nguyen, Matthew Fisher, Aaron Hertzmann, Szymon Rusinkiewicz
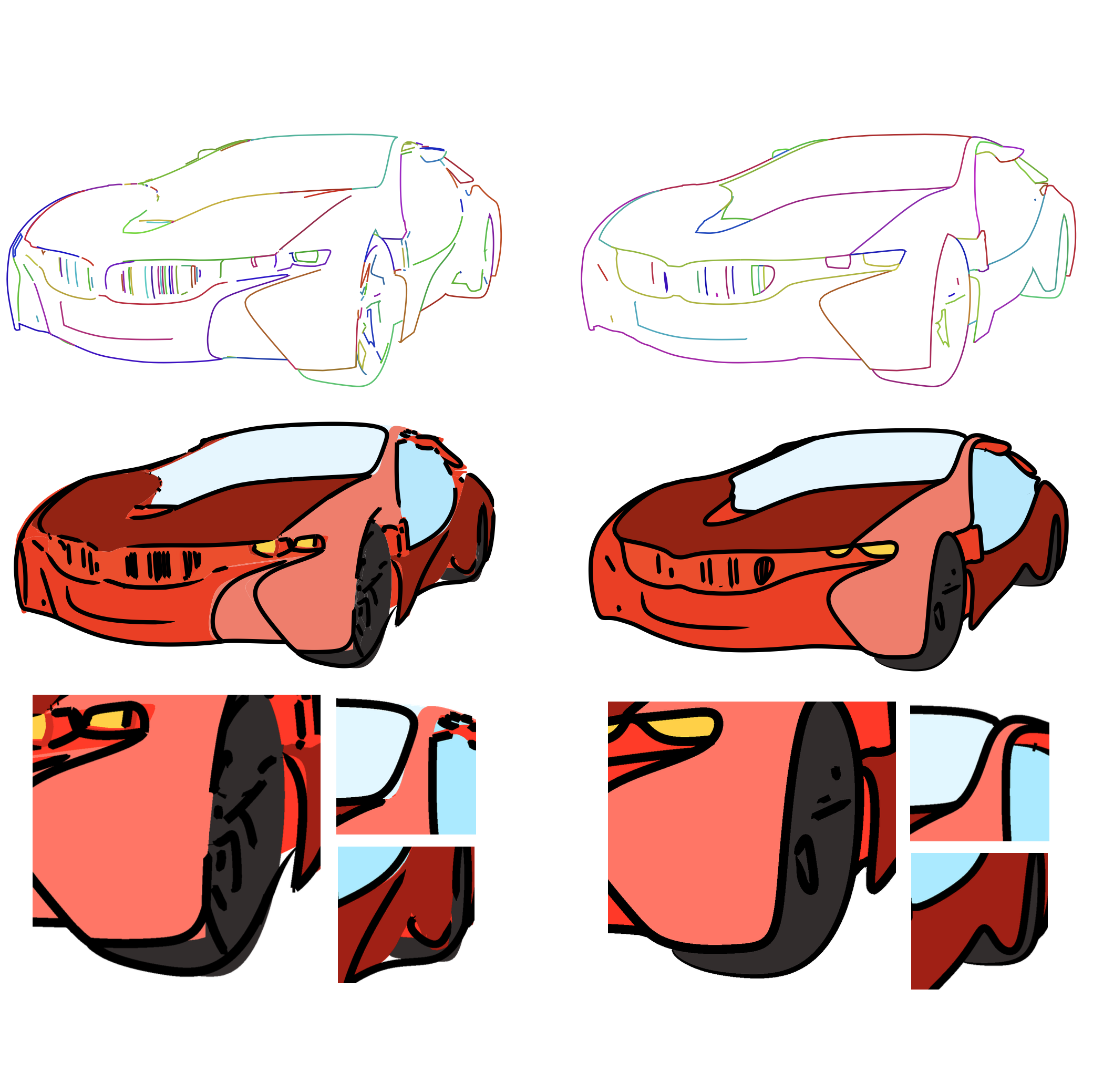
Shape-conveying line drawings generated from 3D models normally create closed regions in image space. These lines and regions can be stylized to mimic various artistic styles, but for complex objects, the extracted topology is unnecessarily dense, leading to unappealing and unnatural results under stylization. Prior works typically simplify line drawings without considering the regions between them, and lines and regions are stylized separately, then composited together, resulting in unintended inconsistencies. We present a method for joint simplification of lines and regions simultaneously that penalizes large changes to region structure, while keeping regions closed. This feature enables region stylization that remains consistent with the outline curves and underlying 3D geometry.

Vivien Nguyen, Sunnie S.Y. Kim (Equal Contribution)
The iMet 2020 dataset is a valuable resource in the space of fine-grained art attribution recognition, but we believe it has yet to reach its true potential. We document the unique properties of the dataset and observe that many of the attribute labels are noisy, more than is implied by the dataset description. Oftentimes, there are also semantic relationships between the labels (e.g., identical, mutual exclusion, subsumption, overlap with uncertainty) which we believe are underutilized. We propose an approach to cleaning and structuring the iMet 2020 labels, and discuss the implications and value of doing so. Further, we demonstrate the benefits of our proposed approach through several experiments. Our code and cleaned labels are available at this https URL.

Xuaner Zhang, Kevin Matzen, Vivien Nguyen, Dillon Yao, You Zhang, Ren Ng
In cinema, large camera lenses create beautiful shallow depth of field (DOF), but make focusing difficult and expensive. Accurate cinema focus usually relies on a script and a person to control focus in realtime. Casual videographers often crave cinematic focus, but fail to achieve it. We either sacrifice shallow DOF, as in smartphone videos; or we struggle to deliver accurate focus, as in videos from larger cameras. This paper is about a new approach in the pursuit of cinematic focus for casual videography. We present a system that synthetically renders refocusable video from a deep DOF video shot with a smartphone, and analyzes future video frames to deliver context-aware autofocus for the current frame.
Master's Thesis
CS 182: Deep Learning

CS 194-26: Computational Photography
CS 294-164: Computational Color